I decided to write this post as I was unable to find all this information in one place when I was learning Terraform Provider internals to be able to contribute to either of them. There are tons of useful docs (both Hashicorp’s owned and publicly available blog posts) on the topic, however, I was feeling a lack of some “centralized” articles with a minimum of code and maximum of explanations.
As I said in my previous post, almost each widely used tool has a very simple idea in the basement, and Terraform is not an exclusion.
Here I want to share my knowledge regarding Terraform Providers’ internal structure using simple words and examples (I hope so 😀). All examples will be for Terraform Provider for AWS, but other providers works exactly the same way as Terraform Provider development approach strictly defines all aspects of communication between Terraform and Cloud/Service API.
What is Terraform on a high-level
Terraform is a command-line tool that allows you to manage some resources within Service or Cloud providers by simply defining these resources in text files, following particular syntax and code style.
For example, you can define an AWS S3 bucket resource in a bucket.tf file like so:
resource "aws_s3_bucket" "dmz_config" {
bucket = "my-bucket"
}Then run terraform apply - and Terraform will create a bucket in AWS with all attributes specified (in our case, AWS S3
bucket with the my-bucket name will be created).
After that, you can change values in the bucket.tf file and run terraform apply again - Terraform will update this S3
bucket to match new values you just provided.
To do all this magic, Terraform makes extensive use of Service/Cloud API (in our case, AWS API).
Main parts of Terraform ecosystem
A long time ago Terraform was distributed as a single binary, including both Core and Cloud API communication logic inside. That was pretty monstrous architecture because of two reasons (there were much more actually, but these two seem to be the most “painful” for me):
- Cloud APIs are extended/updated/fixed very often; to have all of their features supported in Terraform, it was needed to have pretty fast development cycles for Terraform itself. Otherwise, Terraform will lack these new features or resources support that are offered by API.
- due to the first reason, it was hard to separate responsibilities and maintain the whole codebase as a single application
That’s why Terraform maintainers and developers decided to split Terraform into more independent parts:
- Terraform Core
- Terraform Plugins
Now, terraform tool just contains Terraform Core inside that manages internal data and communicates with separated
plugins in order to do some useful work.
What is a Plugin
Plugins are of two types:
- Providers
- Provisioners
Here we will talk about Providers only.
In simple words, Provider is an interlayer between Terraform Core and Cloud API.
There are the following Provider’s responsibilities:
- Converts data from Terraform’s internal structure into a structure, required by Cloud API methods;
- Invokes CRUD functions of Cloud API (which consumes data converted in the previous step);
- Converts Cloud API’s response data object into Terraform’s internal data structure;
- Implements a logic for managing connection to Cloud API (usually via creating and configuring
clientobjects from Cloud SDK libraries).
How Terraform Core interacts with Terraform Plugins (Providers)
Terraform Providers work on talking to Cloud/Service Provider APIs. They have nothing to do with
terraform internal mechanisms such as tf files parsing, syntactical analysis, resource graph building and so on.
Let’s take a look at the scheme below and follow the steps that are done by different parts of Terraform ecosystem when
you run terraform init,terraform plan or terraform apply commands.
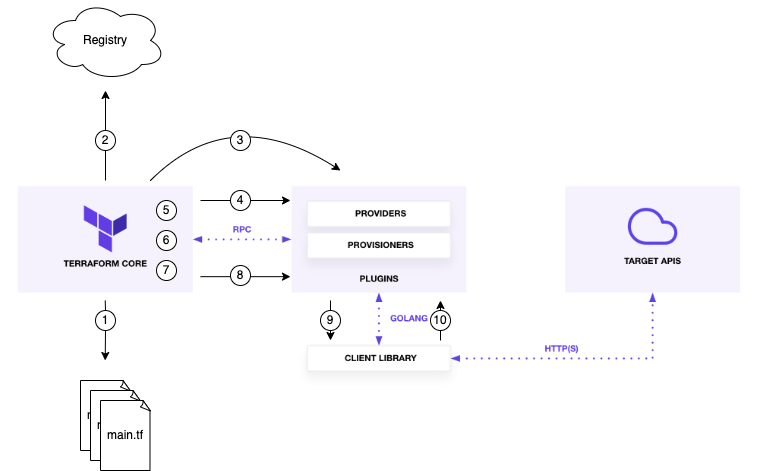
1. Terraform Core: Checks code and gets a list of required plugins (providers and provisioners)
terraform binary reads all *.tf files in the working directory and tries to build a list of providers that are
needed for managing resources defined in .tf files. For example, we have defined the next main.tf file:
resource "aws_s3_bucket" "dmz_config" {
bucket = "my-bucket"
force_destroy = false
}Terraform sees that there is an aws_s3_bucket resource, and it gets the first part of the resource type which is aws
and understands that it’s needed to have Terraform Plugin for AWS locally.
Each resource that is managed by either of Terraform Providers, MUST include a provider name in the resource type as a prefix. For example:
"aws_iam_role"(awsis a name of provider),"azurerm_storage_account"(azurermis a name of provider),"template_file"(templateis a provider name).
2 & 3. Terraform Core: Gets all required plugin binaries
Terraform binary checks local directories for Plugin binary. If Plugin is missing, then Terraform goes to Terraform Registry
and tries to find the Plugin with a required version (or with the latest version when a version is not explicitly
specified in .tf files). If Terraform finds it, the Plugin binary will be downloaded, if not - an error will be returned
and terraform process will be halted.
There are other possible ways of locating Provider binaries (not only from the Terraform Registry), however, they are out of the scope of our story and do not change the general approach.
4. Terraform Core: Starts Plugin binary as a separate process
Plugin binary is a standalone executable file (e.g. terraform-provider-aws_v4.16.0_x5 for Terraform Plugin for AWS,
version 4.16.0) and you can even run it as other tools. However, it will not do any
useful work for you as it’s designed to be called by Terraform Core. In case you try to run Plugin binary separately, you’ll
see the following self-explaining output:
$ ./terraform-provider-aws_v4.16.0_x5
This binary is a plugin. These are not meant to be executed directly.
Please execute the program that consumes these plugins, which will
load any plugins automaticallyTerraform talks to Plugins via RPC following a pre-defined protocol (I will talk about protocols later) so Terraform just start Plugin binary as a separate process.
After starting the Plugin binary, it tries to talk to the Plugin and get its schema and a list of available resources.
Schema defines all attributes that can be configured for a particular resource.
Schemais one of the most important and basic entities in Terraform. In simple words, Schema defines all attributes and fields that you can use during writing terraform code for your resource or for provider configuration. For example, you are trying to writetfcode for an AWS IAM role and here you can use such arguments as"name","description","path","assume_role_policy"and so on. All these arguments are defined within theaws_iam_roleresource’s schema.
Resource represents one or more objects within Service or Cloud Provider (e.g. AWS EC2 instance for Cloud or Github repo for Service).
Then Terraform Core checks if the schema is consistent and tries to validate your code in .tf files against the schema.
It throws an error if there are any fields in your .tf files that are not defined in the schema or if there are some
required fields defined in the schema but missing in your .tf files.
5. Terraform Core: Builds resources graph
Terraform Core builds a Directed Acyclic Graph (DAG) of your resources, where resources are nodes and dependencies
between them are edges.
6. Terraform Core: Reads a state file
Terraform Core reads local or remote state file.
State file is a JSON file that contains resource attribute values collected from resource object in the Cloud. State
file can contain only the values which are defined in resource schema. Moreover, state file is empty until the first run
of terraform apply command. No real resources in Cloud - no values in the state file.
Also, it contains some general information about the whole resource stack described in your .tf files.
7. Terraform Core: Detects difference between statefile and real resources state
Terraform Core runs through the graph, processes nodes (resources) one by one and tries to understand which resources
should be touched. It does it via comparing desired resource state described in your .tf files with the actual
resource state in the cloud or the system.
Then Terraform Core collects all discrepancies and prepares a plan of execution - a list of resources that must be
created/modified/deleted because they are not in the state that you specified in your .tf files.
8. Terraform Core: Invokes CRUD functions inside Plugin binary to manage resources
Terraform Core invokes CRUD functions inside Plugin via RPC saying it what should be executed.
CRUD functions are defined for each resource within Provider (we’ll take a look at it in the second part of the story). Terraform Providers follow strict rules for defining CRUD functions and mapping them to resources.
9. Plugin: Executes logic defined in CRUD functions
In most cases, CRUD functions that are defined for a particular resource within a Plugin just call the required CRUD functions of the client library (e.g. AWS SDK for GoLang).
10. Plugin: Waits for response from client library functions.
Plugin waits for a response from client library, then unpack this response data into objects consumed by Terraform Core, updates state and returns data to Terraform Core.
What’s next?
I’m going to write another post regarding Terraform Provider internals but more focused on Go code. We’ll take look on providers’ and resources’ schemas, CRUD functions and RPC communication protocols in terms of communication between Terraform Core and Terraform Plugins.
Meanwhile, I just provide you with a list of useful links:



Leave a comment